
Handling Missing Data with Imputation Using Pandas
Jul 14, 2023

Incomplete data is a common reality in the world of data analysis. These missing values can be due to a variety of reasons, such as input errors, technical problems or simply lack of information. However, it is critical to address these values effectively to avoid distortions in our analyses. In this project, we will explore how to handle missing data using the Pandas library in Python.
Importing Libraries and Custom Functions
We will start by importing the tools needed to work with data in Python. Pandas is a powerful library that allows us to work with datasets efficiently.
Loading Data
The first step is to load our data in a structure that Pandas understands: a DataFrame. You can load data from different sources, such as CSV files, Excel or databases. In this case the load will be carried out by importing nhanes.load, Nhanes is a survey conducted by the US government that collects health information from the US population and has been arranged in a specialized Python package to be able to process and manipulate it.

Data Processing
Once we have our data loaded, it is essential to analyze the amount and distribution of missing values in our dataset. This will give us an idea of how much information is missing and whether it is significant. Before deciding how to handle missing values, it is important to understand their impact on the results we are looking for.

Viewing and Eliminating Missing Values
Visualizing the number of missing values in each column can help us identify patterns and decide how to proceed. A bar chart can be useful to represent this information visually. In some cases, eliminating rows or columns with missing values may be an option, but this decision should be made after careful consideration of the implications.
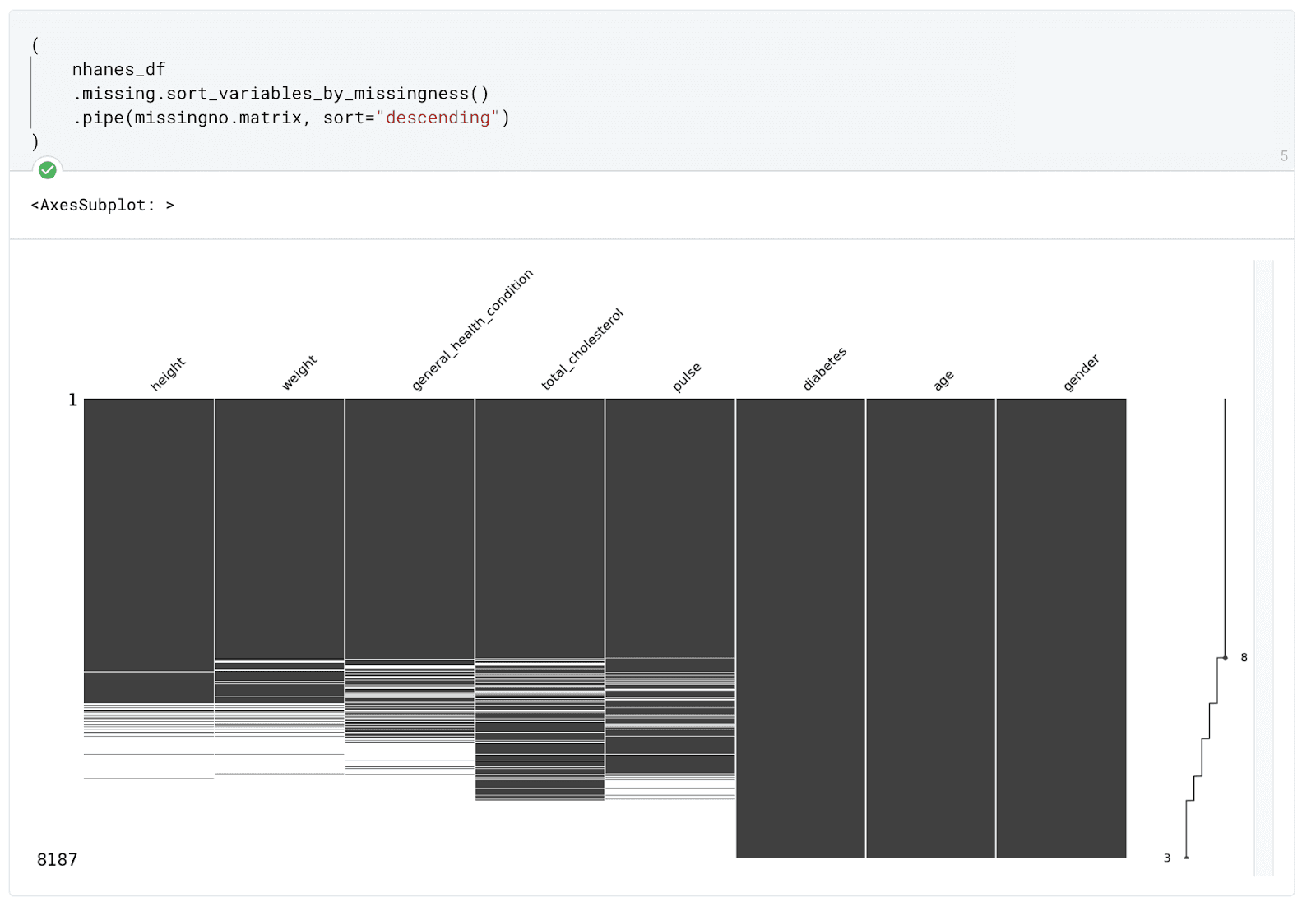

Imputation of Missing Values
If we choose not to remove missing values, we can resort to imputation. Imputation involves replacing missing values with reasonable estimates based on other available data. This technique can preserve the integrity of our data sets and prevent the loss of valuable information.
Some examples of missing data allocation:
Single-value imputation:

Backward or forward fill imputation:

Interpolation imputation:


Conclusion
In summary, handling missing data is an essential skill in data analysis. The choice between removing or imputing values depends on the context and the potential impact on our analyses. It is crucial to understand the nature of missing values and make informed decisions. Pandas offers powerful tools to deal with these scenarios, allowing us to maintain the quality and accuracy of our data analysis. Remember that each data set is unique, so it is important to adapt these techniques to your particular situation.